Andrej Karpathy Just Made RAG Obsolete — And All You Need Is Three Folders
- Haggai Philip Zagury
- Agentic ai , Dev ops
- April 7, 2026
Table of Contents
**TL;DR
**Andrej Karpathy just published a gist called LLM Wiki that replaces complex RAG pipelines with three plain-text folders: raw, wiki, and output. A coding agent reads your raw material, builds a compounding wiki, and your LLM context window becomes genuinely smarter over time — no vector database, no embeddings infrastructure, no DevOps expertise required. I’ve been doing a version of this for four years on my wiki. Now that Karpathy has a name for it, maybe everyone else will catch up.
The Man Who Names Things
There’s a pattern with Andrej Karpathy: he doesn’t just do research, he names things that already exist in the air — and once he names them, they become real. He coined “vibe coding” in early 2025, and within weeks it was in every job description and conference talk. On March 27 he dropped AutoResearch on GitHub — a system that gives an AI agent a small but real LLM training setup and lets it experiment autonomously overnight, running 5-minute training iterations, evaluating results, and keeping or discarding changes in a loop. The repo accumulated a staggering number of stars in days.
Then, two days ago (April 4, 2026), he published a single GitHub gist titled LLM Wiki. No fanfare. Just a markdown file. And it’s already at 5,000+ stars.
That’s the thing about Karpathy: the quieter the drop, the bigger the idea.
What’s Wrong with RAG (And Why Everyone Just Accepts It)
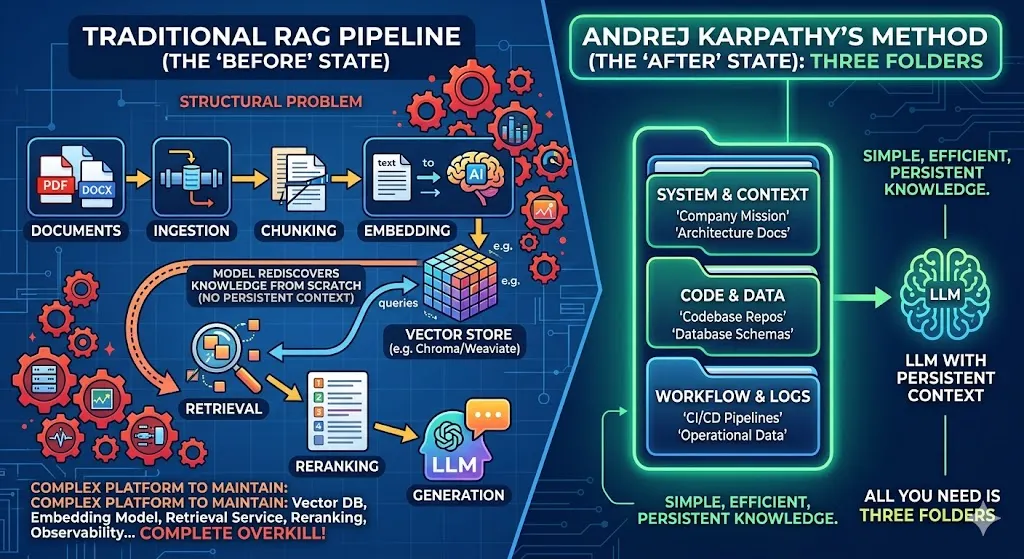
RAG — Retrieval-Augmented Generation — is the standard playbook when you want an LLM to work with your documents. Upload files, chunk them, embed them into a vector store, retrieve relevant chunks at query time, stuff them into the context window, generate an answer. It works.
But there’s a structural problem buried in that workflow that most people ignore: the LLM is rediscovering knowledge from scratch on every single query.
You ask about your architecture decision from six months ago. The RAG system retrieves three chunks that mention it. The model synthesizes an answer. You close the session. Next time you ask a related question, the process starts over. The model has no memory of what it synthesized before. Your knowledge base doesn’t grow — it just gets retrieved differently each time.
For DevOps and platform engineers specifically, there’s a second problem: building a proper RAG system is work. You need a vector database (Chroma, Weaviate, Qdrant, pgvector — pick your poison), an embedding model, an ingestion pipeline, a retrieval service, a reranking layer, and ideally some observability to know when it’s hallucinating. That’s a non-trivial platform to maintain, and it’s complete overkill if what you actually want is for your AI assistant to understand your company’s context.
Three Folders and a Coding Agent
Here’s Karpathy’s core insight from the LLM Wiki gist:
Instead of building a system that retrieves and re-synthesizes knowledge on every query, build a wiki once and keep it updated. Let a coding agent do the heavy lifting.
The pattern is simple:
**raw/**— dump everything here. Meeting transcripts, articles, PDFs, docs, notes, podcast summaries. This is your source of truth, unprocessed.**wiki/**— this is where your coding agent writes and continuously updates structured wiki pages synthesized from your raw material. Each page covers a topic, concept, or domain.**output/**— the artifacts the agent produces: reports, summaries, analyses generated by querying the wiki.
The key mechanic: the wiki compounds. When you add new raw material, the agent doesn’t start from scratch — it updates the relevant wiki pages, cross-references existing knowledge, and the whole structure gets incrementally smarter. Your context window, when you eventually talk to the LLM, is pre-populated with synthesized knowledge rather than raw chunks.
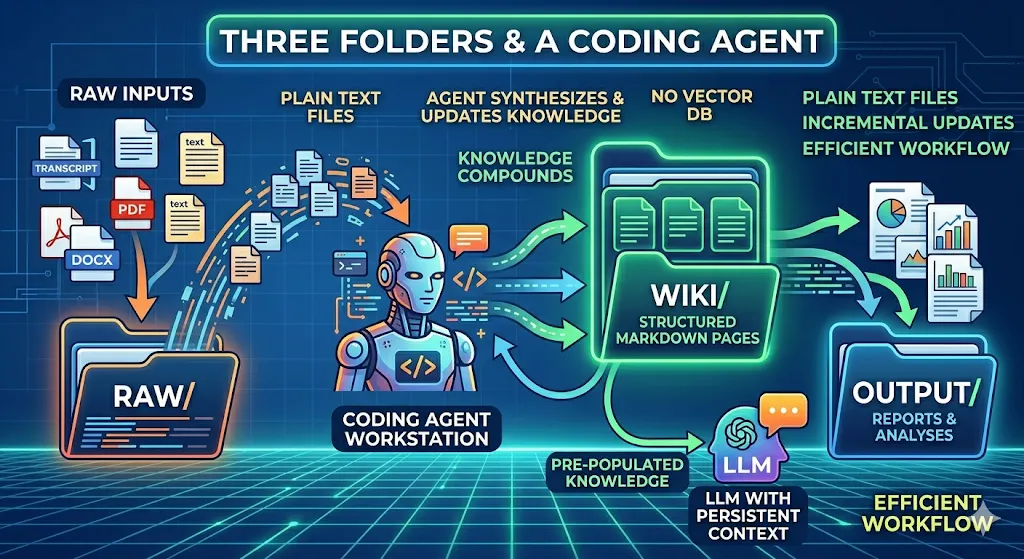
No vector database. No embedding pipeline. No infrastructure. Just plain text files.
The Obsidian Angle (And Why It’s Not Just for Researchers)
If you’re a knowledge worker, there’s a natural tool that maps directly onto this pattern: Obsidian. It’s a free, local-first markdown editor where everything is just plain text files on your computer. No cloud lock-in, no subscriptions, no vendor — just folders and .md files.
Combine Obsidian’s folder structure with a coding agent like OpenCode, Claude Code, or any agentic framework that can read and write files, and you have exactly what Karpathy describes. Your raw/ folder is your inbox. Your wiki/ folder is your growing knowledge graph. The agent is the engine that turns chaos into structure.
Karpathy’s gist is explicitly designed to be dropped into any LLM agent as an idea file — it even says so in the opening lines. You paste it into your agent of choice, and the agent collaborates with you to build out the specifics. The pattern is the interface.
What I’d add for people running actual businesses (not just personal research): the three-folder pattern becomes even more powerful when your raw/ folder contains operational data — customer transcripts, support tickets, incident retrospectives, architecture decision records, planning docs. Point a coding agent at that, let it build the wiki/, and you have a living organizational memory that any team member can query.
I’ve Been Doing This for Four Years
I’ll be honest: when I read the LLM Wiki gist, my first reaction was “that’s exactly what I’ve been doing with my portfolio site.”
For over four years — long before AI agents were the default way to work with text — I’ve been maintaining a structured repository of notes, references, and synthesized content as the backbone of portfolio.hagzag.com. The discipline of keeping raw material organized and building synthesized artifacts on top of it is not a new idea. It’s essentially how any competent researcher or knowledge worker manages long-term context.
What’s new is that a coding agent can now do the synthesis work automatically. That changes the economics completely. Previously, maintaining a wiki meant constant manual effort. Now the effort is in feeding the raw/ folder — which you’re probably doing anyway — and the agent handles the rest.
What’s also new is that Karpathy has named it, documented it, and pointed thousands of people at it. And that matters. When the person who co-founded OpenAI, wrote the definitive neural network tutorials, and produced a 3.5-hour video on how LLMs actually work tells you to delete your RAG pipeline and replace it with three folders — you listen.
If you haven’t watched that video yet: carve out the 3.5 hours. It’s the best investment you’ll make in understanding what these tools actually are, under the hood. The content is priceless and IMHO ages remarkably well.
What This Means If You’re Not a Researcher
The LLM Wiki pattern, combined with something like qmd (a local on-device search engine for markdown that layers BM25 + vector search + LLM reranking on top of your files), gives you a knowledge system that:
- Runs entirely on your machine
- Has no recurring infrastructure costs
- Compounds over time instead of starting fresh every session
- Doesn’t require a single line of infrastructure code
For platform engineers and DevOps practitioners who’ve watched their teams build and maintain increasingly complex RAG systems for internal tooling — this is the “wait, could we just not?” moment. Sometimes the right architecture is a folder structure and a disciplined agent loop.
Conclusion
Karpathy’s LLM Wiki is not a product, a framework, or a platform. It’s a pattern — a way of thinking about knowledge and LLMs that’s fundamentally different from the retrieval-first model most of us have been building on top of for the last two years.
The shift: instead of asking “how do I retrieve the right information at query time?”, ask “how do I build a knowledge base that’s already synthesized by the time I query it?”
Three folders. A coding agent. Plain text. That’s the whole system.
Start with your raw/ folder. Drop everything in. Point an agent at it. Let it build your wiki. You might be surprised how quickly it starts to feel like your AI actually knows your context — because it does.
Resources
- LLM Wiki gist by Karpathy
- AutoResearch — autonomous ML research agent
- qmd — on-device markdown search engine
- Karpathy’s blog
- Deep Dive into LLMs like ChatGPT (3.5hr video)
I’d love to hear your thoughts in the subject, feel free to reach out — you know where to find me ;)
Your sincerely, HP


