The Agent Cost Wars — Updated: GLM-5, M2.7, and What the Leaderboard Actually Tells Us
- Haggai Philip Zagury
- Agentic ai
- March 31, 2026
Table of Contents
TL;DR A week ago I published a piece about MiniMax M2.5’s “$1/hour agent” promise and called it the dawn of always-on intelligence. Since then, the leaderboard moved — fast. GLM-5 dethroned M2.5 as the top open-weight model, M2.7 shipped with the same aggressive pricing but unconfirmed licensing, and Gemini 3.1 Pro quietly became the price-performance king among flagships. This is my attempt to challenge my own earlier post with updated numbers from Artificial Analysis, and share some careful impressions on what this means for practitioners heading into the second half of 2026.
Introduction
A few weeks back I started working on “The $1,892 Agent: MiniMax M2.5 and the Dawn of Always-On Intelligence”. The core thesis was straightforward: at $0.30/$1.20 per million input/output tokens, MiniMax M2.5 made continuous agentic workloads economically viable for the first time. I ran cost projections, compared to Claude Opus pricing, and got excited about what “always-on agents” could look like for DevOps and SRE teams.
Since then the world moved ….
In the six weeks since MiniMax M2.5, at least four major model releases reshaped the landscape.
- GLM-5 from Zhipu AI took the #1 open-weight crown on Artificial Analysis.
- Kimi K2.5 introduced “Agent Swarm” parallelism.
- Qwen3.5 dropped with native vision.
And just four days ago, MiniMax shipped M2.7 — a proprietary, self-evolving successor that matches Opus 4.6 on SWE-Pro while keeping the same $0.30/$1.20 pricing.
I felt it was only fair to challenge my own narrative with updated data. What follows is my personal reading of the current state — not a definitive ranking, but a practitioner’s impression based on publicly available benchmarks and pricing as of March 2026.
What the Leaderboard Says Today
The Artificial Analysis Intelligence Index (v4.0) is my go-to reference for cross-model comparison. It’s not perfect — no single benchmark is — but it aggregates 10 evaluations spanning reasoning, coding, knowledge, and agentic tasks.
Here’s where things stand as I see them today:
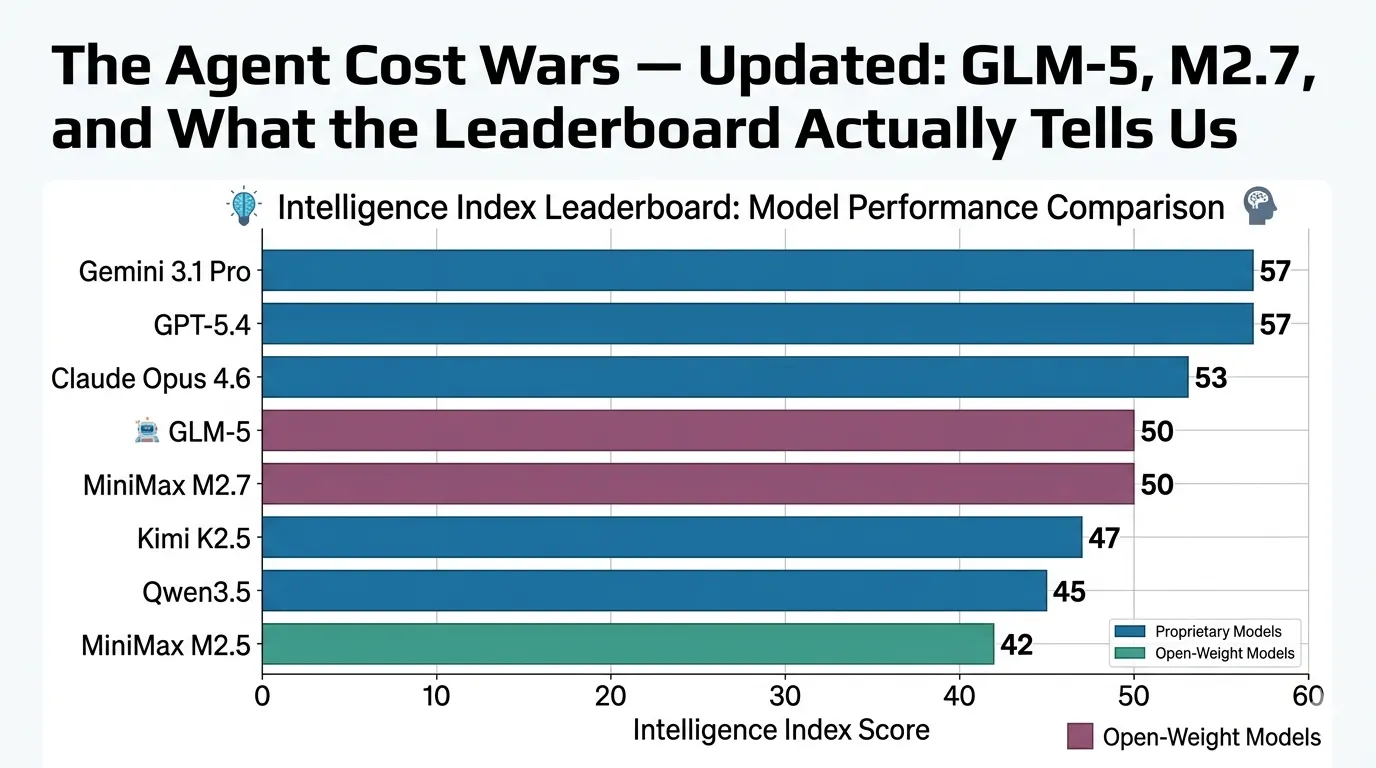
Proprietary Flagships: Gemini 3.1 Pro Preview and GPT-5.4 share the top spot at 57. Claude Opus 4.6 follows at 53 (with adaptive reasoning pushing higher on some tasks). These are the models you use when accuracy is non-negotiable and you can absorb the cost.
Open-Weight Leaders: GLM-5 sits at 50 — the first open-weight model to crack that threshold. It’s a 744B MoE (40B active) trained entirely on Huawei Ascend chips, which is a geopolitical story in its own right. Kimi K2.5 follows at 47, and Qwen3.5 at 45.
The MiniMax Arc: M2.5 scored 42 on that same index — respectable, but clearly a tier below GLM-5 and the flagships. M2.7 just launched and already scores 50, matching GLM-5 — but notably, it’s now proprietary. That’s a significant shift from MiniMax’s earlier open-weight positioning.

The caveat I want to be explicit about: These are snapshot numbers. Artificial Analysis runs evaluations at a specific point in time, and models often improve with provider-side optimizations. I’m presenting the data as I found it — your mileage may vary depending on workload, prompt engineering, and provider choice.
The Pricing Picture — It’s More Nuanced Than I Thought
In my original post, I focused heavily on MiniMax’s headline pricing. Looking at it again with more models in the mix, the picture is more nuanced:
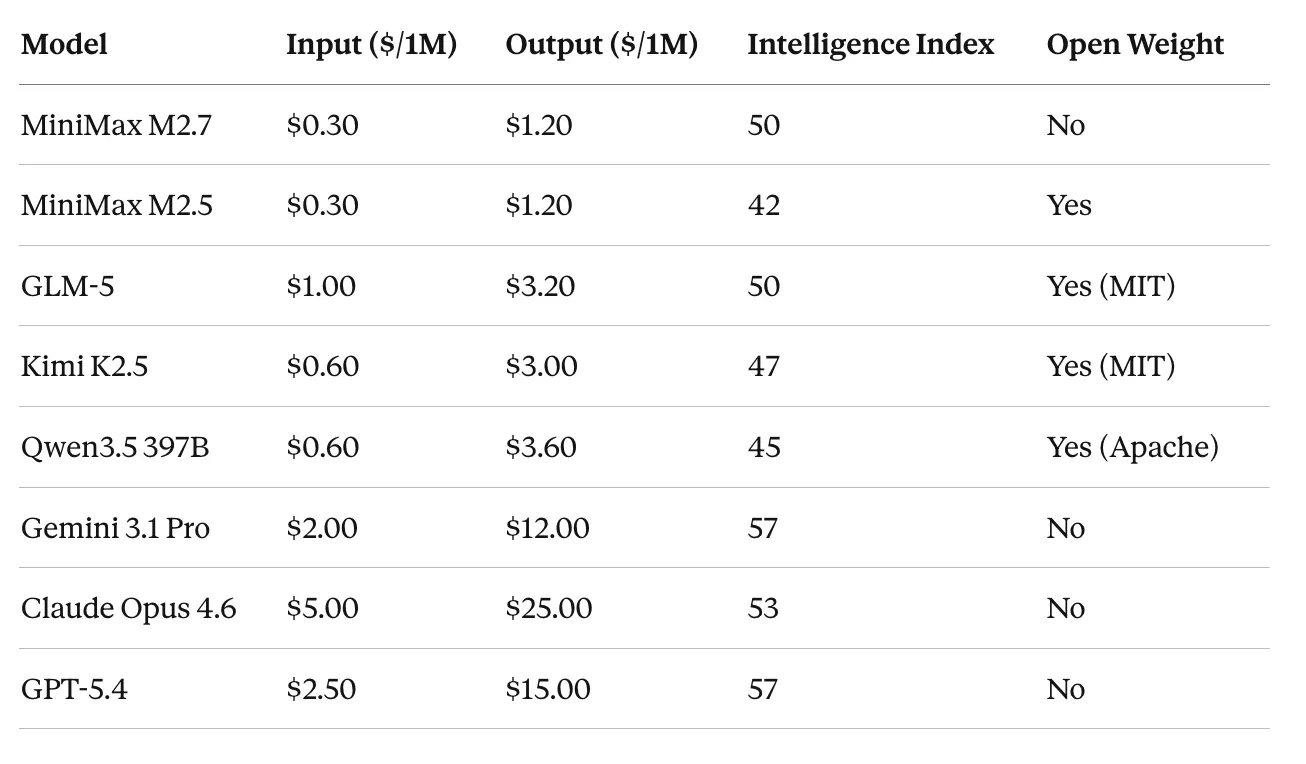
Sources: Artificial Analysis, official provider pricing pages. Prices verified as of March 2026.
A few things jump out at me:
MiniMax’s cost story holds up — but with an asterisk M2.7 at $0.30/$1.20 with an Intelligence Index of 50 is arguably the best value-for-intelligence ratio on the board. But it’s now proprietary. If open weights matter to you (and for many enterprises, they do), GLM-5 gives you the same intelligence score at roughly 3× the cost — still dramatically cheaper than the proprietary flagships.
Verbosity is a hidden cost This is something I underestimated in my original post. Artificial Analysis noted that M2.5 generated 56M output tokens during evaluation, M2.7 generated 87M, and Kimi K2.5 generated 89M — versus a median of ~17–20M for comparable models. When models produce 3–5× more tokens per task, the effective cost per completed task goes up significantly, even if the per-token price is low.
**Gemini 3.1 Pro is the quiet winner for price-performance at the flagship tier **At $2.00/$12.00 with an Intelligence Index of 57, it’s offering top-tier intelligence at less than half the cost of Claude Opus and GPT-5.4. If you’re running production workloads where you need the absolute best reasoning and you’re comparing flagships, Gemini is hard to beat on pure economics right now. That said, pricing is only one dimension — model behavior, API reliability, tool use patterns, and ecosystem integration all matter in production.
What I Got Wrong (And Right)
Let me be honest about where my original post holds up and where it doesn’t:
What still stands: The core economic argument — that sub-$1/hour agent workloads are now viable — is more true than ever. M2.7 reinforces this. The trajectory of cost compression is undeniable, and the practical implication for DevOps teams running overnight batch agents, code review pipelines, and infrastructure analysis is real.
What I undersold: The competitive landscape. I framed M2.5 as a somewhat unique disruptor. In reality, Q1 2026 saw an avalanche of capable, affordable models. GLM-5 matched or exceeded M2.5 on intelligence while being fully open-weight under MIT license. Kimi K2.5 brought agent parallelism as a first-class feature. The disruption isn’t one model — it’s the entire open-weight ecosystem accelerating.
What I didn’t see coming: MiniMax going proprietary with M2.7. Their open-weight strategy was a key part of the M2/M2.5 narrative. The shift to closed weights for their flagship raises questions about the long-term direction. It also means that if you built tooling around self-hosting M2.5, the upgrade path isn’t straightforward.
Impressions on What This Means for Practitioners in 2026
These are my personal impressions, not predictions carved in stone. The landscape moves too fast for certainty.
Coding agents are becoming commoditized — fast. Gemini 3.1 Pro hits 80.6% on SWE-Bench Verified. GLM-5 sits at 77.8%. MiniMax M2.7 is competitive in the mid-50s on SWE-Pro. Six months ago, these benchmarks were dominated by a single model family. Now there are half a dozen options within a few percentage points of each other, spanning a 10× price range. For coding-specific agent workloads, the “which model” question is becoming less important than the “which orchestration” question.
On agentic real-world tasks specifically, Artificial Analysis’s GDPval-AA benchmark (which measures economically valuable work across real occupations) shows M2.7 at Elo 1494 — ahead of GLM-5 (1406) and Kimi K2.5 (1283), though still behind GPT-5.4 (1667) and Claude Opus 4.6 (1606). The frontier flagships maintain a meaningful edge on the tasks that most closely resemble production DevOps and SRE workloads.
The $1/hour floor is becoming a ceiling for commodity tasks. I suspect that by end of 2026, running a basic coding agent continuously will cost less than $0.30/hour for most batch workloads. The competitive pressure from Chinese open-weight models, combined with aggressive pricing from MiniMax, is pushing all providers toward lower price points. This doesn’t eliminate the need for premium models — complex, multi-file architectural reasoning still benefits from Claude Opus or GPT-5.4 level capability — but the floor for “good enough” is rising rapidly.
Self-evolving models change the game, but we’re early. M2.7’s claim of handling a significant portion of its own RL training workflow is fascinating, and to me, a little unsettling. If models start materially improving themselves through production usage, the traditional model release cycle we’ve been tracking on leaderboards may become less relevant. I’m watching this space closely but I wouldn’t bet on it being production-stable for enterprise use cases yet.
Open weight ≠ accessible. GLM-5’s 744B parameters require serious GPU infrastructure. Kimi K2.5 at 1T parameters is even more demanding. The “open-weight” label increasingly means “you can inspect and fine-tune it if you can afford the compute” rather than “you can run it on your laptop.” For most practitioners, the API is still the practical consumption model — which brings you back to the pricing table above.
For DevOps and platform engineering specifically, I see the most immediate impact in three areas:
- Automated code review at scale — you can now afford to run every PR through a capable model
- Infrastructure drift detection — feeding Terraform state into an agent for continuous analysis
- Incident response augmentation — agents that can parse logs, correlate events, and suggest runbooks
The cost barrier for these use cases has effectively collapsed.

The Bigger Pattern
Stepping back from individual models, the pattern I see is this: intelligence is converging while price is diverging. The gap between the #1 model (57) and the best open-weight model (50) is only 7 points. The price gap between them can be 50× or more. That convergence-divergence dynamic — more intelligence for less money, from more providers — is the real story of 2026.
As someone who’s been in this industry for 25+ years, I’ve seen similar patterns before. When compute got cheap, we got cloud. When CI/CD got cheap, we got DevOps. When inference gets cheap — and it is getting cheap, fast — we’ll get a new category of always-on, continuously-running intelligent systems that we don’t even have a good name for yet.
I’m not sure what to call it. But I’m pretty sure it’s happening.
Conclusion
This post is my way of keeping myself honest. The MiniMax M2.5 article captured a real moment, but the moment has already evolved. If you’re making model selection decisions today, I’d encourage you to look at the full landscape — check Artificial Analysis for the latest numbers, run your own evaluations on your actual workloads, and don’t anchor on a single model’s headline pricing without accounting for verbosity, latency, and effective task completion cost.
The leaderboard will look different again in a week. That’s my point, and consdering that — my last post on this subject ;)
Resources
- Artificial Analysis LLM Leaderboard — The primary data source for this analysis
- MiniMax M2.7 Announcement — MiniMax’s official model page
- GLM-5 on Hugging Face — Model card and benchmarks
- My original post: “The $1,892 Agent” — The article this post challenges

