The $1,892 Agent: MiniMax M2.5 and the Dawn of Always-On Intelligence
- Haggai Philip Zagury
- Agentic ai , Dev ops
- March 21, 2026
Table of Contents
TL;DR
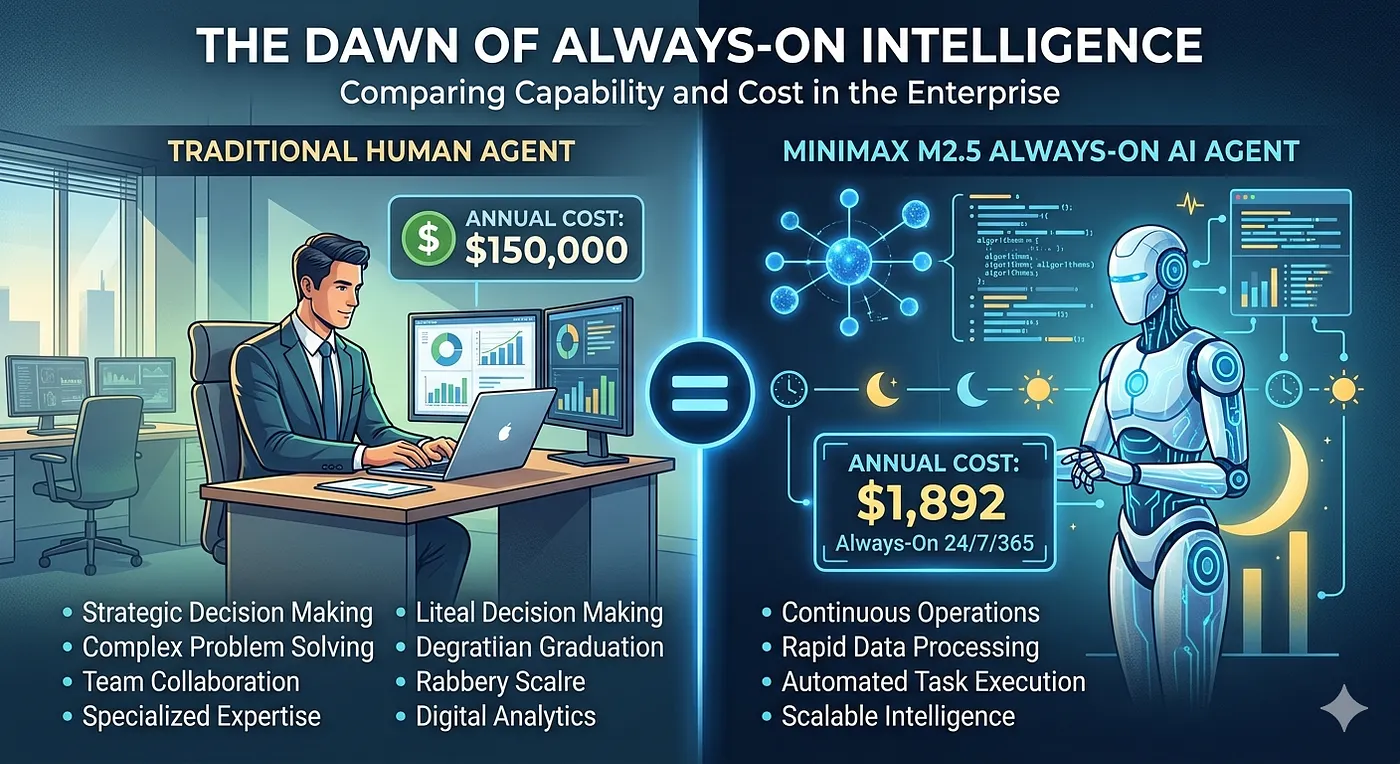
MiniMax M2.5 is a 230B-parameter model that activates only 4% of its weights per token — yet scores 80% on SWE-bench Verified, putting it neck-to-neck with Anthropic Opus 4.6 at roughly 3% of the cost. At ~$1,892/year for a continuously running agent, the “always-on agent” is no longer a thought experiment. The cost of intelligence is approaching the cost of electricity, and Jevons’ Paradox says: demand is about to explode.
Introduction
A few months back, I wrote about The Cost of Conversations — the hidden bill behind every token, every prompt, every “quick question” to an AI model. The premise was simple: AI usage feels free until it isn’t, and if you’re building agentic systems that run 24/7, you need to think about total cost of ownership the same way you’d budget for cloud infrastructure.
That post was written in a world where running a frontier-quality agent continuously was genuinely expensive — a luxury reserved for well-funded teams or use cases with clear, measurable ROI.
About a month ago MiniMax M2.5 changed the equation.
This isn’t just another model release. It’s a signal — one of the clearest we’ve seen — that the cost of intelligence is converging with the cost of compute. And for those of us building agentic DevOps pipelines, autonomous reviewers, and always-on platform assistants, that changes everything.
What Is MiniMax M2.5 (what about M2.7) ?
MiniMax M2.5 is the latest iteration in the M2 family — following M2, M2.1, and now M2.5, with each generation shipping roughly every 50 days (I hear M2.7 is doing even better …). The architectural headline: 230 billion total parameters, but only ~10 billion activated per token via Mixture of Experts (MoE).
That 4% activation rate isn’t new as a concept — Deepseek and others have used MoE for a while. What’s new is what MiniMax achieved within that constraint:
- 80% on SWE-bench Verified — comparable to Anthropic Opus 4.6
- ~$0.30 per million input tokens / $1.20 per million output tokens
- ~100 tokens/second inference speed (roughly 2× the speed of heavier alternatives)
- Model weights to be open-sourced shortly (same architecture as M2.1, which already runs locally quantized)
When you compare this against GLM 4.6, Kimi K2, and Deepseek V3.2 on the SWE-bench open-weights leaderboard (see chart below), MiniMax M2.5’s value proposition becomes hard to ignore.
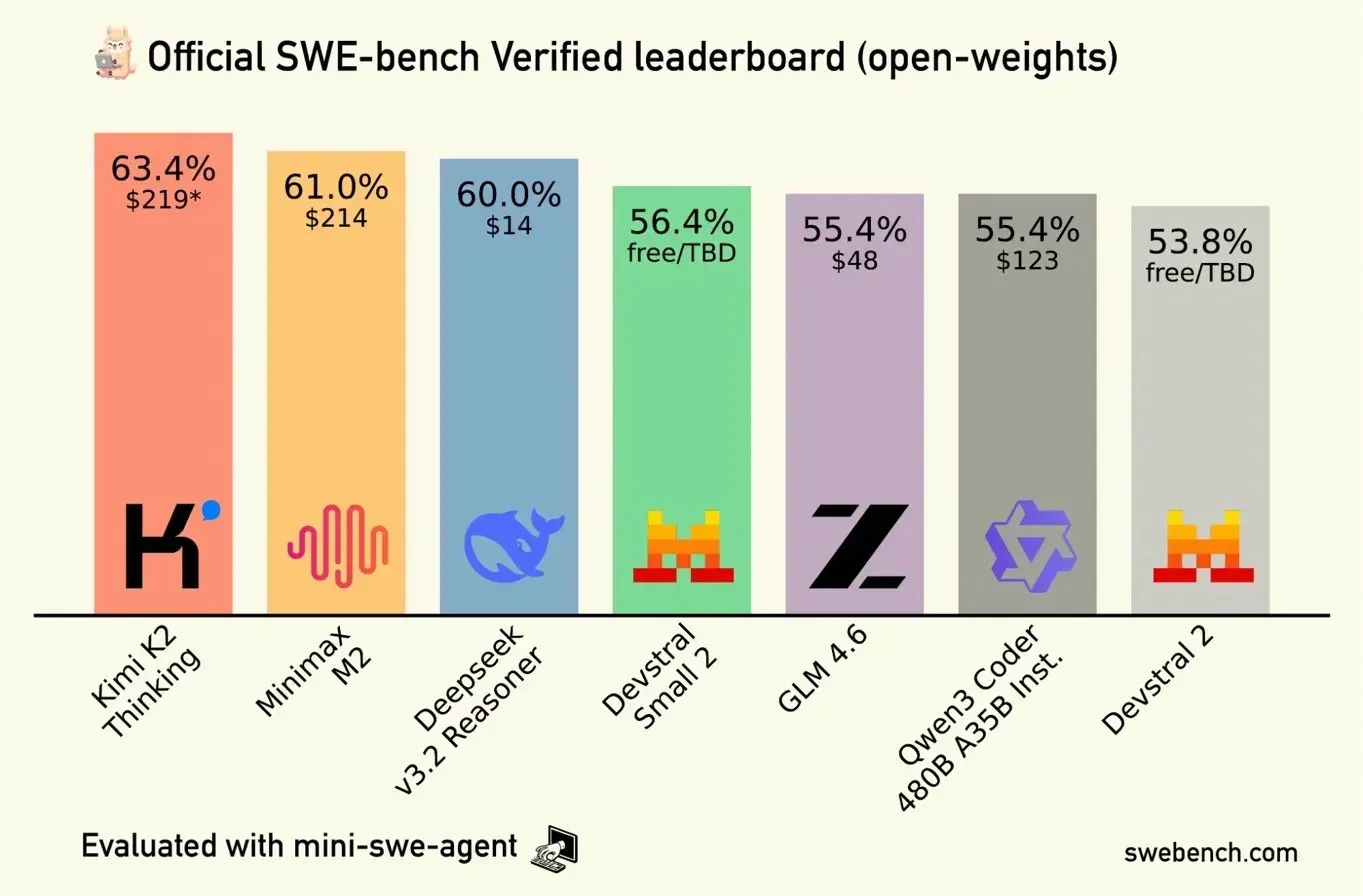
Note: The leaderboard above reflects the open-weights category. Closed/proprietary models are tracked separately, and the landscape shifts weekly.
Why SWE-bench Matters to Us as Software Engineers 🤔🤔🤔
If you’re not familiar with SWE-bench, here’s the short version: it’s a benchmark that measures an AI agent’s ability to resolve real GitHub issues from real open-source repositories — not synthetic puzzles, not coding trivia, actual pull-request-worthy patches.
From a practitioner perspective, SWE-bench is one of the few benchmarks that maps meaningfully to our world. When I’m evaluating whether to wire a model into a CI pipeline as a code reviewer, or give it autonomy to triage production alerts and suggest remediations, I don’t care how it does on math olympiad problems. I care how it performs on tasks that look like: “given this failing test and this codebase, write the fix.”
SWE-bench Verified (the stricter variant) filters the dataset further to ensure the issue-fix pairs are unambiguous and well-formed. It’s the closest proxy we have to “can this model do junior developer work?” — which is exactly the bar we need for autonomous agents in the SDLC.
A score of 80% means 8 out of 10 real issues resolved autonomously. For context, most teams would be thrilled with a human junior developer closing 80% of straightforward issues without supervision.
The Always-On Agent — From Dream to Line Item
Ever since tools like Moldbook Agents and OpenClaw went viral (and yes, opencode users — more on that in a moment), the idea of an “always-on agent” captured people’s imagination: an AI that’s perpetually listening, triaging, acting, and preparing context — not just answering questions when asked.
The problem? Cost.
When I discussed the cost-of-conversations framework earlier, the math on always-on agents was sobering. Running a frontier model 24/7 — even conservatively — was in the range of tens of thousands of dollars per year for a single agent thread. Real TCO made this a VP-level budget conversation, not a team-level infrastructure decision.
MiniMax M2.5 runs the math differently.
Assuming continuous operation at 50 tokens/second output for a full year:

These are illustrative estimates based on published token costs and continuous operation assumptions. Actual costs will vary with traffic patterns and caching.
The gap in capability between Opus 4.6 and MiniMax M2.5 on SWE-bench? Roughly 2 percentage points. The gap in cost? Roughly 34×.
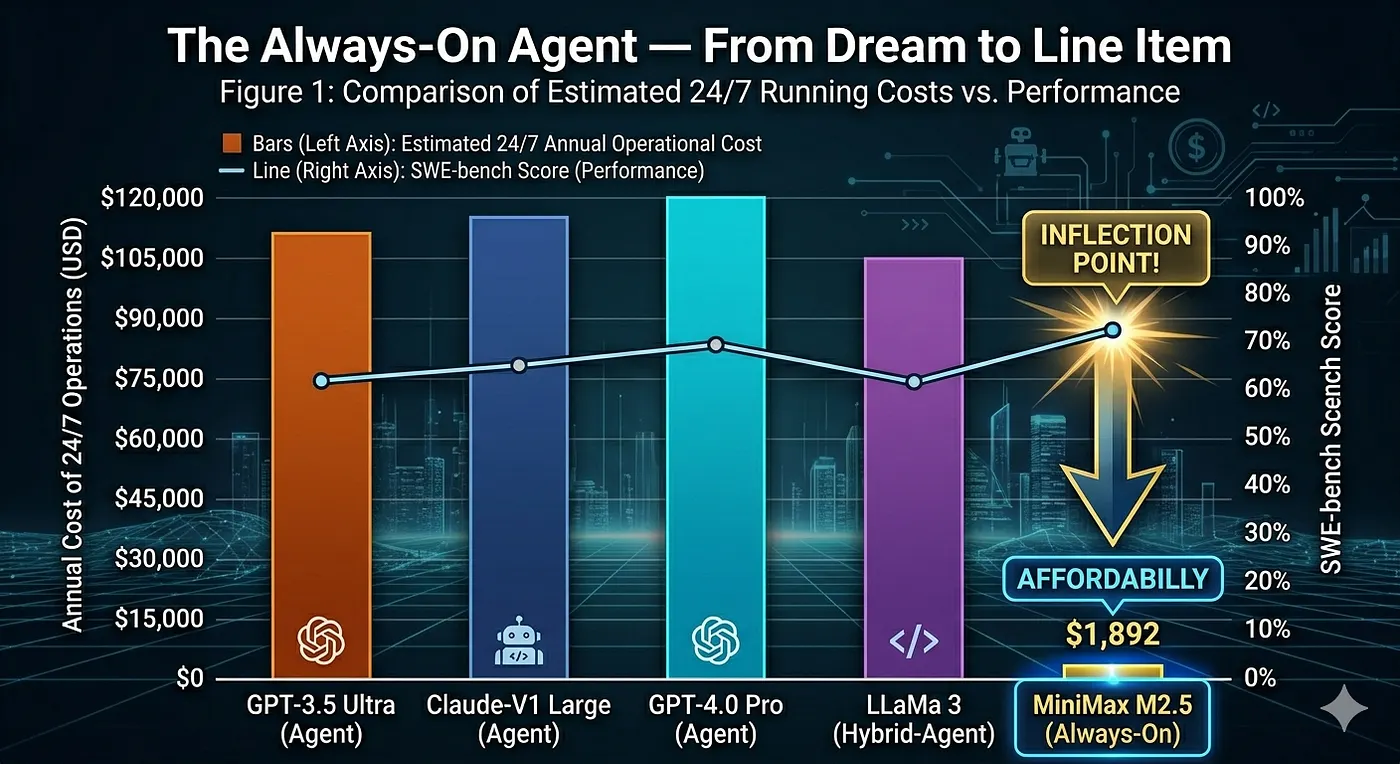
For DevOps use cases — think: always-on PR reviewer, incident triage agent, drift detector, IaC auditor — this moves always-on agents from “nice to have” to “justify it like any other tool in the stack.”
A Note for opencode Users
If you’re running opencode — this is directly relevant to you. MiniMax M2.5 is available as a free model on the opencode Zen subscription, and also accessible via the MiniMax paid API.
If you’ve been using opencode with more expensive model backends, swapping in MiniMax M2.5 for your agentic loops (especially for code review, summarization, or refactoring tasks) is worth a serious evaluation. The performance is there. The price is a non-issue.
The Broader Signal: Jevons’ Paradox and the Intelligence Economy
There’s been a lot of noise about the “AI bubble” — and at the center of it is a specific argument: if the cost of intelligence keeps dropping, demand for GPUs will eventually plateau or fall. Companies like Oracle, xAI, and OpenAI are spending tens of billions on GPU infrastructure while models keep getting cheaper and more efficient. That tension has spooked markets.
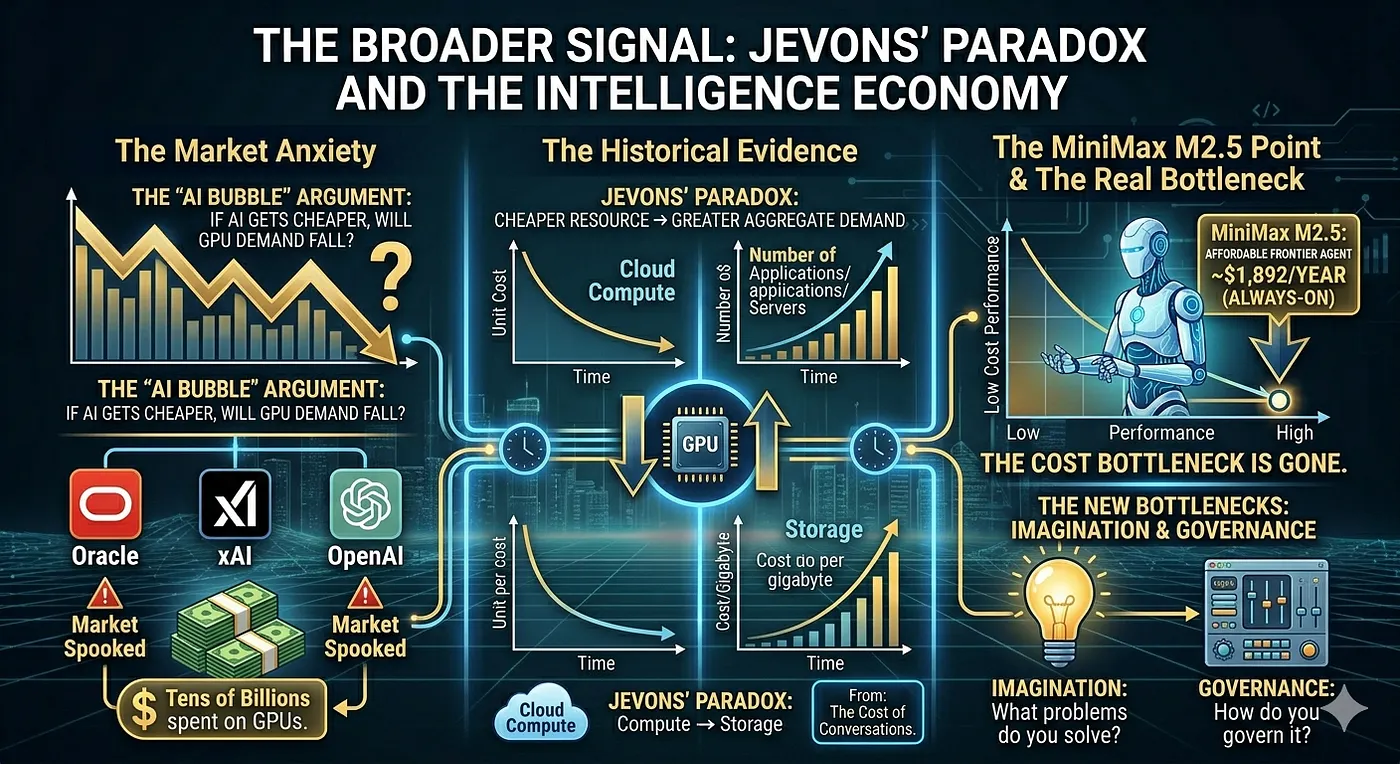
The counterargument — and I think it’s the right one — is Jevons’ Paradox: when a resource becomes cheaper, aggregate demand for it increases, not decreases. We saw this with cloud compute. We saw it with storage. Cheaper AI won’t reduce demand — it will unlock entire categories of use cases that were economically infeasible before.
MiniMax M2.5 is one of the first concrete data points in this direction. At ~$1,892/year for a continuously running, near-frontier-quality agent, the bottleneck is no longer cost — it’s imagination and integration.
As I noted in The Cost of Conversations: the conversation isn’t free, but it’s getting cheaper fast. The question isn’t whether you can afford an always-on agent anymore. The question is: what problem is it solving, and how do you govern it?
What This Means for Platform Teams
Speaking directly to DevOps and platform engineers: the tooling conversation is shifting.
We’re moving from “should we use an AI agent in this workflow?” to “which agent, with which model, at what autonomy level?” The cost variable that used to make that a budget conversation is now closer to “do we need another EC2 instance?” — operational noise, not strategic bloat.
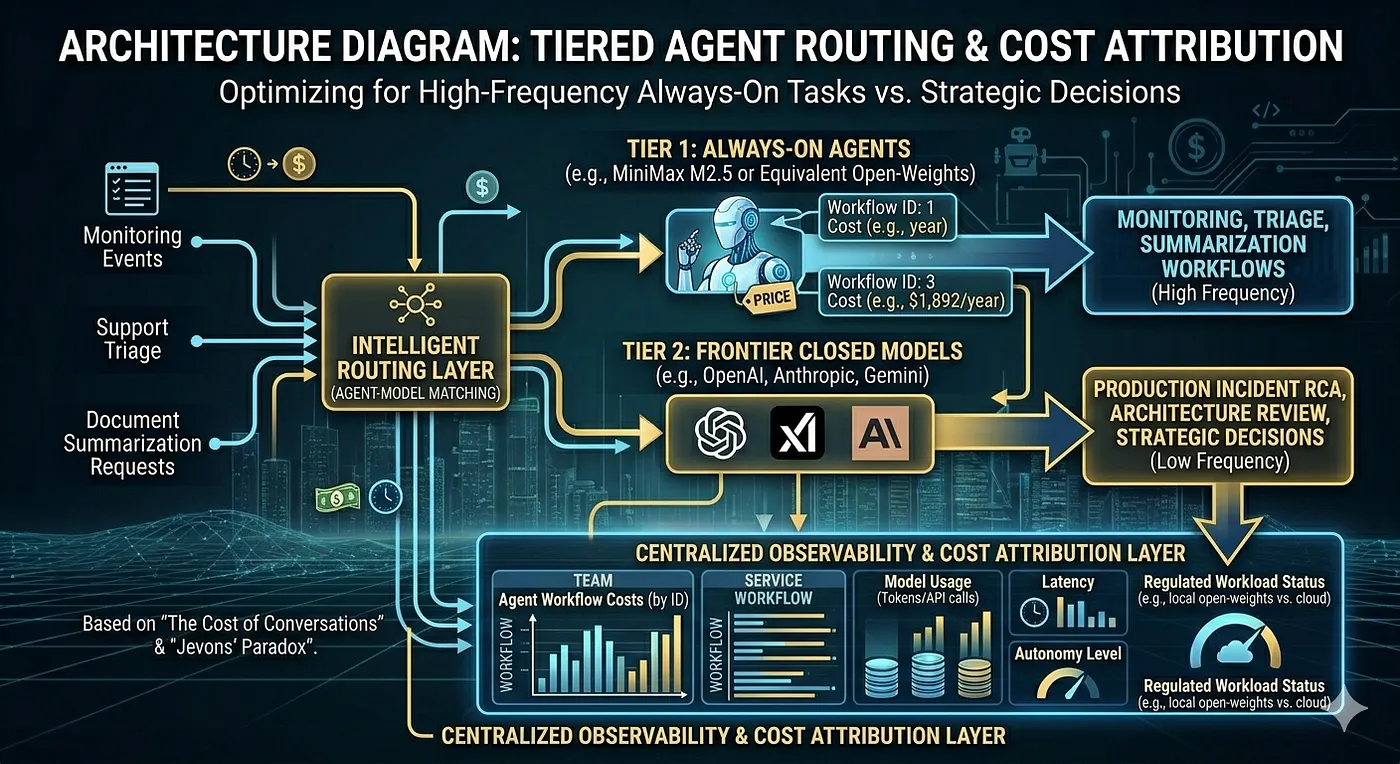
The architecture patterns that follow from this:
- Tiered model routing: Use MiniMax M2.5 (or equivalent) for high-frequency, always-on tasks (monitoring, triage, summarization). Reserve frontier closed models for high-stakes, low-frequency decisions (production incident RCA, architecture review).
- Cost attribution at the agent level: Just like we tag cloud resources per team/service, agent cost needs to be tracked at the workflow level — not lumped into a single API bill.
- Open-weight optionality: With weights being released, running quantized MiniMax M2.5 locally (or on-prem for regulated workloads) is a near-term option — similar to how M2.1’s quantized variant already runs on modest hardware.
Conclusion
The cost of intelligence is approaching the cost of electricity. That’s not hyperbole — it’s math, and MiniMax M2.5 is one of the clearest signals we’ve seen that we’re crossing a threshold.
For those of us who’ve been building toward agentic DevOps — always-on reviewers, autonomous triage, continuous compliance checks — the bottleneck just moved from cost to design. That’s a good problem to have.
The question I’m sitting with now: not can we afford an always-on agent, but what does responsible, well-governed, always-on intelligence look like in a production platform?
More in that in following posts.
Resources
- MiniMax M2.5 on Hugging Face
- SWE-bench Verified Leaderboard
- The Cost of Conversations — Israeli Tech Radar
- opencode — MiniMax M2.5 available free on Zen subscription
- MiniMax Coding Plan — 12% discount available for new and existing users
Originally published on Medium on 2026-03-21. Cross-posted to portfolio.hagzag.com