
Taming the AI Beast: The Role of the LLM Gateway
- Haggai Philip Zagury (hagzag)
- Developer experience ( dev ex)
- August 20, 2025
Table of Contents
In a personal setting, managing AI costs might be a matter of checking your credit card statement. But for an organization with multiple teams, projects, and AI providers, it’s a financial and operational challenge.
This is where a single, central piece of infrastructure — an LLM Gateway — becomes indispensable.
An LLM Gateway is a layer that sits between your applications and all the different AI models (e.g., OpenAI, Anthropic, Google Gemini, open-source models). Instead of each team connecting directly to a different provider, all AI traffic is routed through this one gateway.
This seemingly simple setup provides a wealth of benefits, especially for cost management.
How an LLM Gateway Helps You Track and Control Costs:
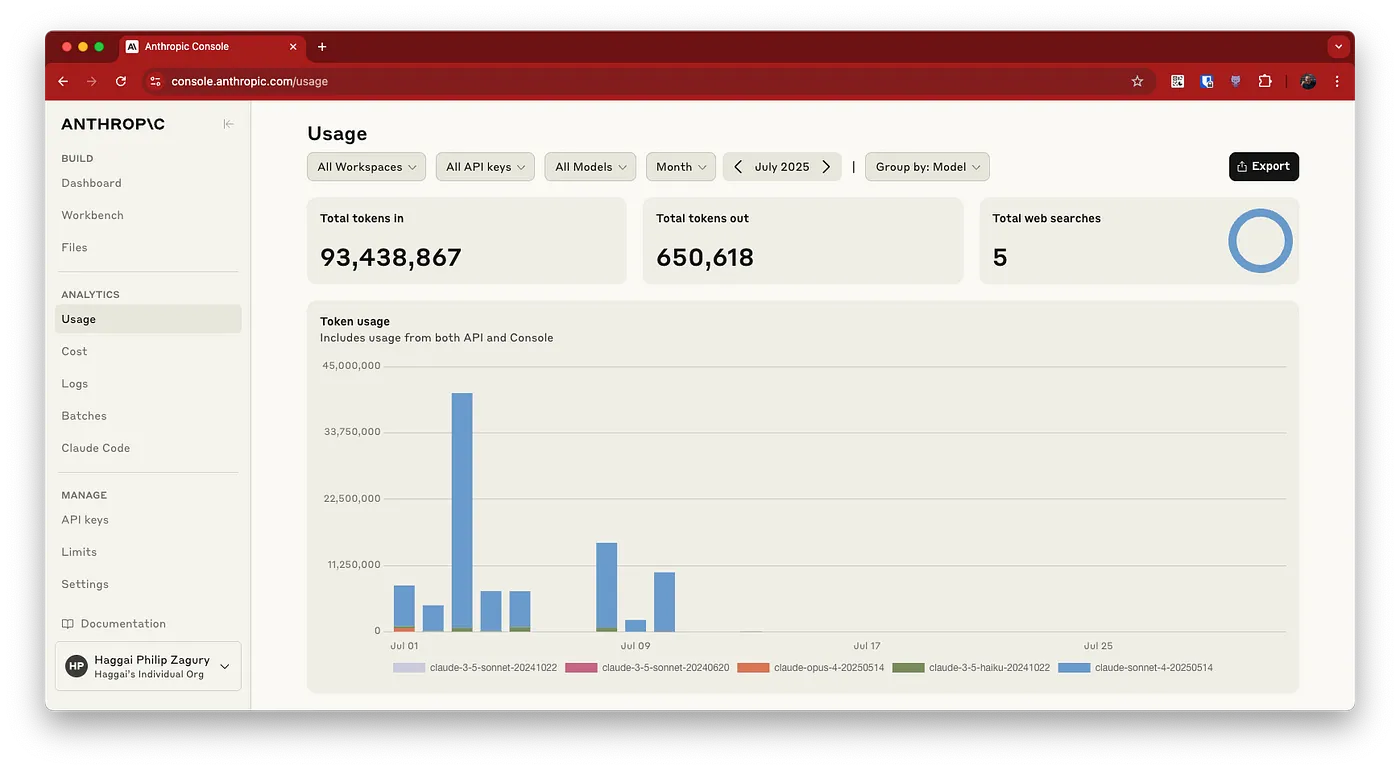
(1) Centralized Visibility and Billing: The most immediate benefit is a single point of truth for all AI usage. Every API call, every token consumed, and every dollar spent is logged and tracked in one place. This ends the chaotic practice of piecing together bills from multiple vendors and allows a central team to get a clear, real-time picture of all AI expenses.
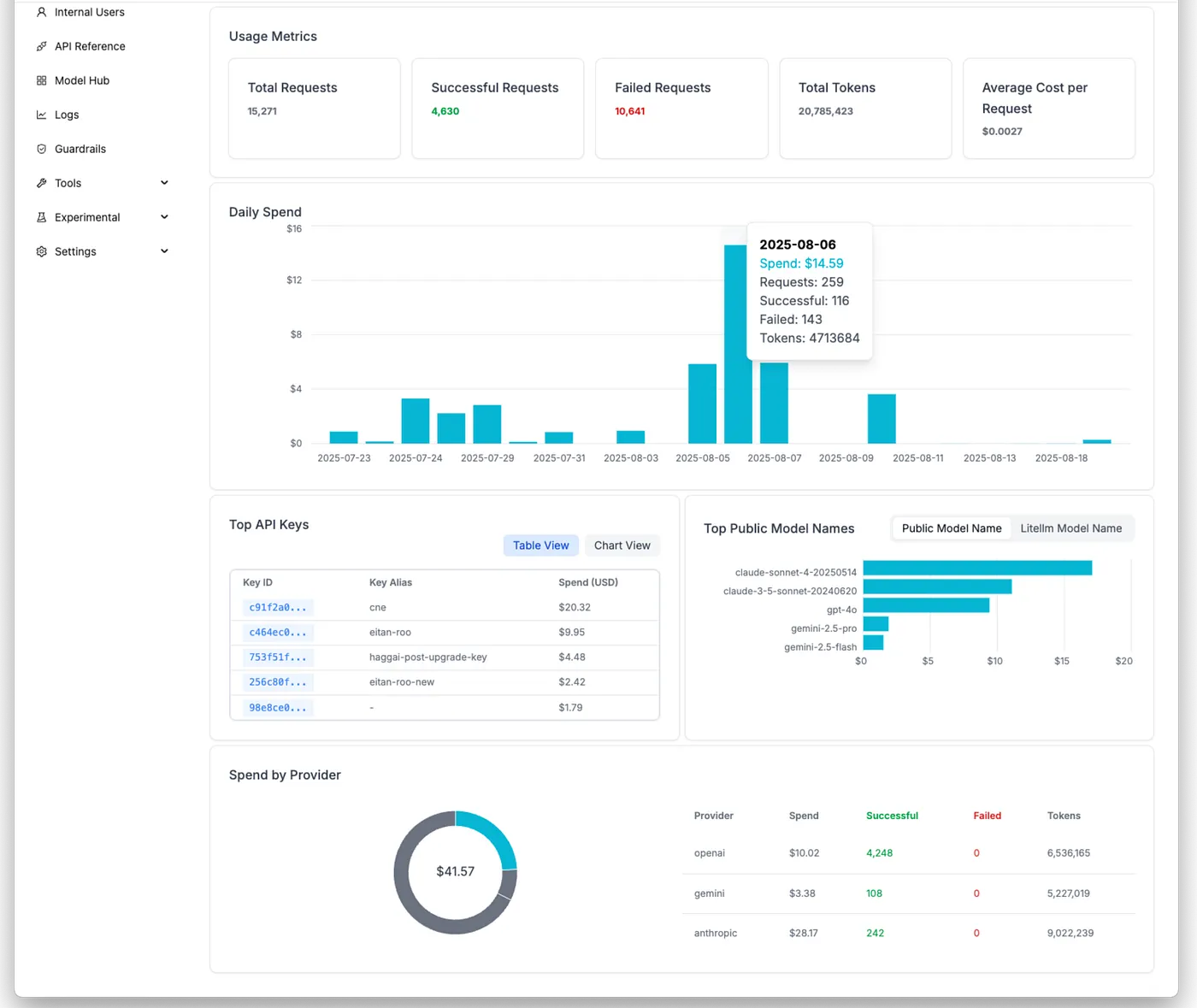
(2) Granular Cost Attribution: An LLM Gateway allows you to tag requests with metadata. This means you can track costs not just by the model used, but also by:
- User or Team: See who is using the most tokens.
- Project or Application: Understand which products or features are the most “AI-hungry.”
- Usage Model: Categorize requests as “Vibing” or “Building” to identify and optimize costly behaviors.
(3) Intelligent Routing for Savings: The gateway acts as a smart traffic controller. Based on the tags or the content of the request, it can automatically route it to the most appropriate and cost-effective model. For example:
- A simple request for a synonym might be routed to a small, cheap, open-source model.
- A complex prompt requiring multi-step reasoning would be automatically sent to an expensive, high-end model like GPT-4.
- This ensures you’re only paying a premium for tasks that genuinely require it, effectively managing your “Vibing” costs.
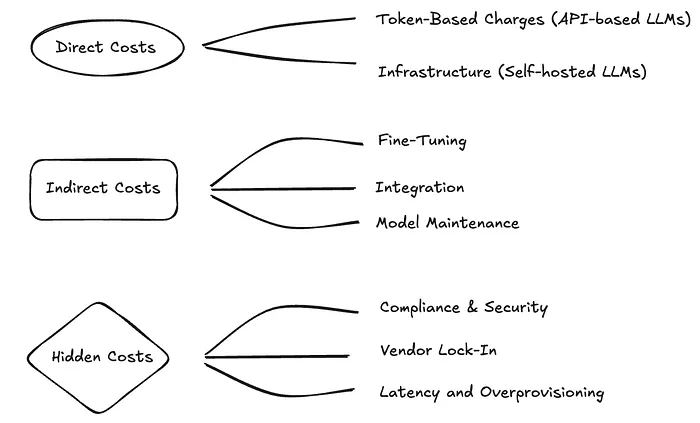
(4) Enforcing Budgets and Limits: With all usage flowing through a single point, you can set hard limits. The gateway can be configured to:
- Alert a team when they’ve used 80% of their monthly budget.
- Throttle a specific user’s token usage if they are exceeding a limit.
- Block requests to an expensive model once a project has hit its allocated spend.
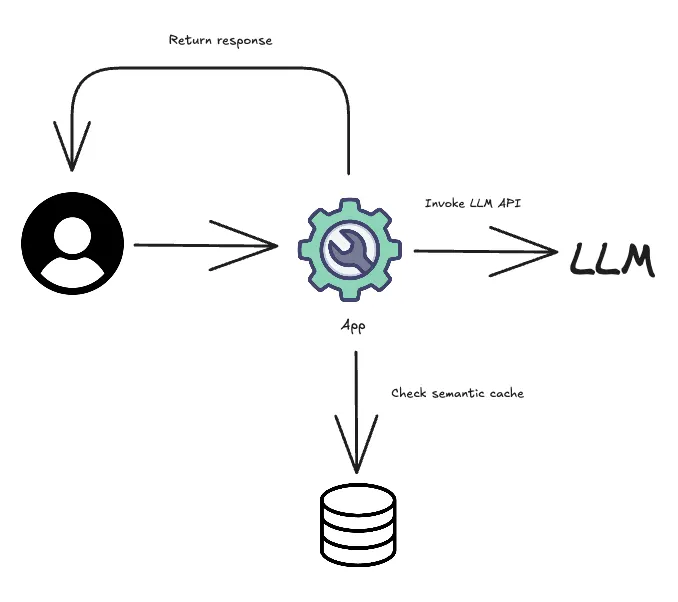
(5) Caching and Optimization: Some gateways offer features like caching. If a team or user asks the same question multiple times, the gateway can serve the cached response without making a new API call to the provider, saving you both time and money.
Moving from Chaos to Control
Without a system for tracking, an organization is left in a state of AI cost chaos. The “Vibing” model, while valuable for quick bursts of creativity, can spiral out of control and lead to surprisingly large bills. By implementing an LLM Gateway, a company moves from an unmonitored “pay-per-token” free-for-all to a strategic, data-driven approach. It brings the power of planning and architecture not just to the AI’s output, but to the entire process of how AI is used and billed.


