Table of Contents
There’s no place like K3d continued — 2 — scaling with KEDA
TLDR; this is a lab used to prove concepts delivered in the production-readiness series I am writing in Tikal’s Tech Radar.
Background
As you may know by now I am quite a big fan of K3d and it looks like i’ve embarked on a* “There’s no place like K3d” series* …, this post is a complementary to the “production readiness series”, i’m in the process of writing part 6 — scaling, and as it took me some time to separate scaling from scheduling which I eventually did in part5, this is my attempt to create an example I can reference in part6 discussing Horizontal Scaling which is very typical of Event Driven Systems / Architectures such as kubernetes.
Event Driven Architecture is at the core of how kubernetes controllers operate each request to the api is written to the key-value store which stores all the api requests in or case a deployment an hpa and a replica-set with a number of pods …
 DALL-E | control loop, HPA and all things related comics style
DALL-E | control loop, HPA and all things related comics style
KEDA & HPA
like many things in kubernetes, kubernetes is a framework which provides a spec you can build on top of, in this case HPA which is a concept of adding replicas in form of additional pods to a deployment.
HPA provides the basic scaling option which includes cpu / memory based scaling whilst KEDA can expand on that technique by augmenting the HPA with its scaleObject as illustrated in the image below.
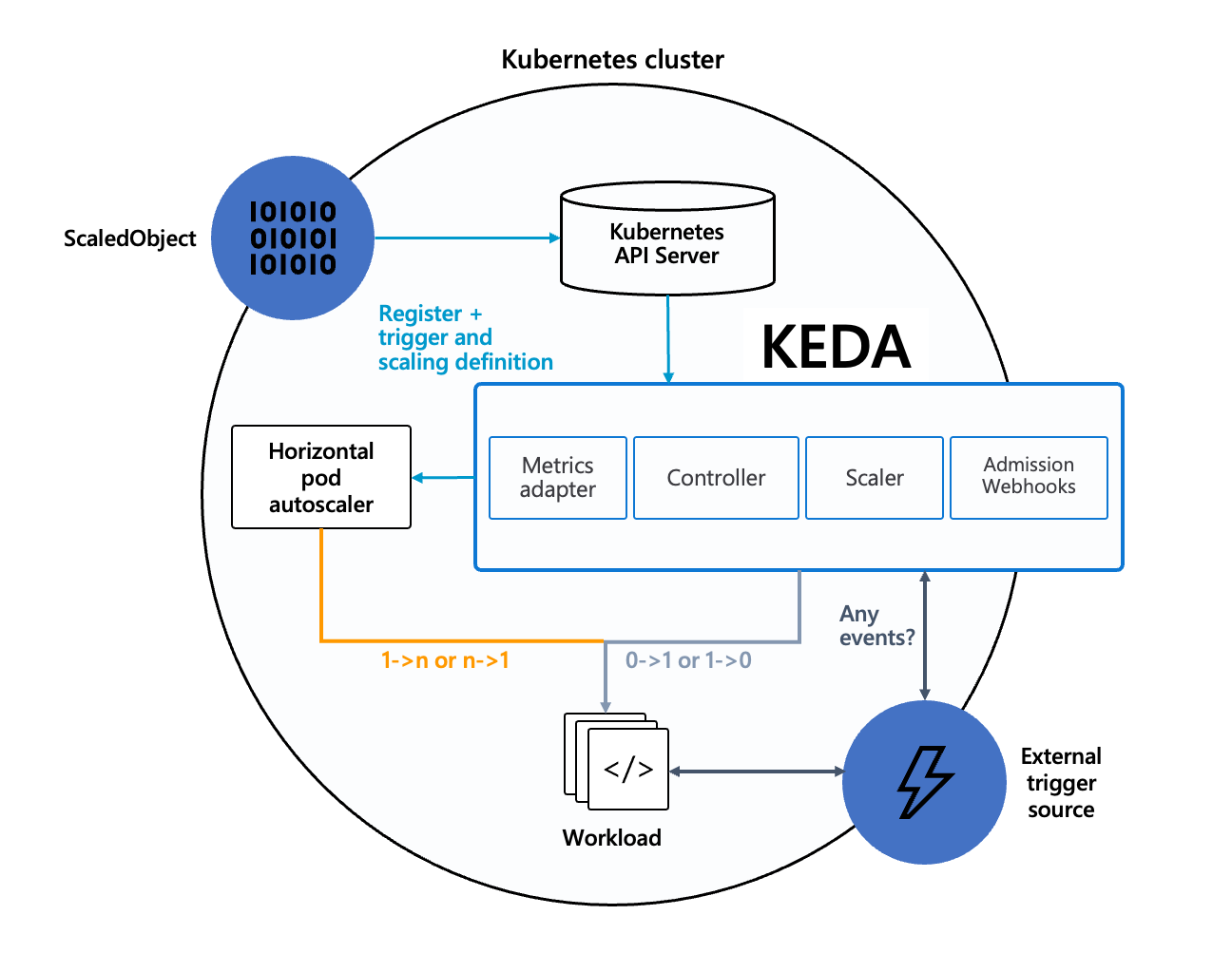 KEDA architecture — no words needed ;)
KEDA architecture — no words needed ;)
Let’s review the use-case and later on continue to a step by step walkthrough.
Usecase:
KEDA basically creates the HPA and monitors it “externally” — which means the keda-controller monitors the keda.sh/v1alpha1 custom resource definition named ScaledObject, in our example we will have keda controller with a redis based scaleObject and in the triggers section of the spec we will request the listName my-queue is equal to 10 … it will basically look like the following object:
cat <<EOF | kubectl apply -f -
apiVersion: keda.sh/v1alpha1
kind: ScaledObject
metadata:
name: redis-scaler
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: web-app
pollingInterval: 15
cooldownPeriod: 30
minReplicaCount: 1
maxReplicaCount: 10
triggers:
- type: redis
metadata:
address: redis-master.keda-demo.svc.cluster.local:6379
listName: my-queue
listLength: "10"
password: ""
databaseIndex: "0"
key: "hits"
type: string
operator: GT
threshold: "2"
EOF
Once applied you can monitor the scaled object:
kubectl get scaledobjects.keda.sh,hpa,deploy -n keda-demo
NAME SCALETARGETKIND SCALETARGETNAME MIN MAX TRIGGERS AUTHENTICATION READY ACTIVE FALLBACK PAUSED AGE
scaledobject.keda.sh/redis-scaler apps/v1.Deployment web-app 1 10 redis True True False Unknown 6h24m
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
horizontalpodautoscaler.autoscaling/keda-hpa-redis-scaler Deployment/web-app 7/10 (avg) 1 10 2 6h24m
NAME READY UP-TO-DATE AVAILABLE AGE
deployment.apps/web-app 1/1 1 1 12h
keda configuration is pretty straight forward and if we add to this some job that populates the redis listName … e.g:
# create a job that uses redis-cli to connect and add items to the my-queue collection
apiVersion: batch/v1
kind: Job
metadata:
name: populate-redis-queue
spec:
template:
spec:
containers:
- name: redis-cli
image: redis:latest
command: ["sh", "-c", "redis-cli -h redis-master.keda-demo.svc.cluster.local -p 6379 lpush my-queue item1 item2 item3 item4 item5 item6 item7 item8 item9"]
restartPolicy: Never
were basically using redis-cli lpush my-queue item1 item2 item3 … command to populate the list if we now examine our resources we should see additional replicas added based on the listName length.
kubectl get scaledobjects.keda.sh,hpa,deploy -n keda-demo
NAME SCALETARGETKIND SCALETARGETNAME MIN MAX TRIGGERS AUTHENTICATION READY ACTIVE FALLBACK PAUSED AGE
scaledobject.keda.sh/redis-scaler apps/v1.Deployment web-app 1 10 redis True True False Unknown 6h24m
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
horizontalpodautoscaler.autoscaling/keda-hpa-redis-scaler Deployment/web-app 7/10 (avg) 1 10 2 6h24m
NAME READY UP-TO-DATE AVAILABLE AGE
deployment.apps/web-app 2/2 2 2 12h
These scaling capabilities are quite commodity nowadays and can simulate “server-less style architecture” from the scale of 0 to n which arn’t just elegant — but cost-effective, especially nowadays which model training based on triggers is in demand.
 DALL-E | Lets create an image saying “switching to hands-on mode” make it in the theme of “kubernetes” “k3d” “hpa” “keda” we want to emphasize the hands-on experience and how important it is to software developers
DALL-E | Lets create an image saying “switching to hands-on mode” make it in the theme of “kubernetes” “k3d” “hpa” “keda” we want to emphasize the hands-on experience and how important it is to software developers
A step-by-step guide for this example
Create a k3d cluster named keda-demo
Deploy keda and redis to store our scaling-list
Deploy a example web-app application deployment using nginx:latest
Deploy a scaleObject that will connect to redis
Deploy a kubernetes job that populates the scaling-list
Let’s get to work …
Create a cluster
k3d cluster create keda-demo
Deploy keda and redis via helm
please note usage of –kube-context k3d-keda-demo
install keda
helm repo add kedacore https://kedacore.github.io/charts helm upgrade –install keda kedacore/keda
–namespace keda
–create-namespace
–kube-context k3d-keda-demoinstall redis via helm disabeling auth for demo purposes
helm repo add bitnami https://charts.bitnami.com/bitnami helm upgrade –install redis bitnami/redis
–set auth.enabled=false
–set architecture=standalone
–namespace keda-demo –create-namespace
–kube-context k3d-keda-demoDeploy a example web-app application deployment using nginx:latest
were starting with 1 replica of nginx:latest container
cat «EOF | kubectl -n keda-demo apply -f - apiVersion: apps/v1 kind: Deployment metadata: name: web-app spec: replicas: 1 selector: matchLabels: app: web-app template: metadata: labels: app: web-app spec: containers: - name: web-container image: nginx:latest resources: requests: memory: “64Mi” cpu: “250m” limits: memory: “128Mi” cpu: “500m” EOF
Deploy a scaleObject that will connect to redis ans suscribe to the my-queue list
redis-scaler for Deployment named web-app
cat «EOF | kubectl apply -f - apiVersion: keda.sh/v1alpha1 kind: ScaledObject metadata: name: redis-scaler spec: scaleTargetRef: apiVersion: apps/v1 kind: Deployment name: web-app pollingInterval: 15 cooldownPeriod: 30 minReplicaCount: 1 maxReplicaCount: 10 triggers:
- type: redis
metadata:
based on the svc name:
“redis-master” . “keda-demo” (namespace) . “svc.cluster.local” (cluster-suffix)
address: redis-master.keda-demo.svc.cluster.local:6379 listName: my-queue listLength: “10” password: "" databaseIndex: “0” key: “hits” type: string operator: GT threshold: “2” EOF
- type: redis
metadata:
Deploy a kubernetes job that populates the scaling-list
cat «EOF | kubectl apply -f - apiVersion: batch/v1 kind: Job metadata: name: populate-redis-queue spec: template: spec: containers: - name: redis-cli image: redis:latest command: [“sh”, “-c”, “redis-cli -h redis-master.keda-demo.svc.cluster.local -p 6379 lpush my-queue item1 item2 item3 item4 item5 item6 item7 item8 item9”] restartPolicy: Never EOF
Review our setup
We can take a closer look at our scaledobject now: take a close look at the status of the resource which indicates what it has done.
kubectl describe scaledobjects.keda.sh -n keda-demo
Name: redis-scaler
Namespace: keda-demo
Labels: scaledobject.keda.sh/name=redis-scaler
Annotations: <none>
API Version: keda.sh/v1alpha1
Kind: ScaledObject
Metadata:
Creation Timestamp: 2024-07-10T14:27:46Z
Finalizers:
finalizer.keda.sh
Generation: 1
Resource Version: 1706
UID: 72dcd626-0122-46f5-9841-cbace93a30aa
Spec:
Cooldown Period: 30
Max Replica Count: 10
Min Replica Count: 1
Polling Interval: 15
Scale Target Ref:
API Version: apps/v1
Kind: Deployment
Name: web-app
Triggers:
Metadata:
Address: redis-master.keda-demo.svc.cluster.local:6379
Database Index: 0
Key: hits
List Length: 10
List Name: my-queue
Operator: GT
Password:
Threshold: 2
Type: string
Type: redis
Status:
Conditions:
Message: ScaledObject is defined correctly and is ready for scaling
Reason: ScaledObjectReady
Status: True
Type: Ready
Message: Scaling is performed because triggers are active
Reason: ScalerActive
Status: True
Type: Active
Message: No fallbacks are active on this scaled object
Reason: NoFallbackFound
Status: False
Type: Fallback
Status: Unknown
Type: Paused
External Metric Names:
s0-redis-my-queue
Health:
s0-redis-my-queue:
Number Of Failures: 0
Status: Happy
Hpa Name: keda-hpa-redis-scaler
Last Active Time: 2024-07-10T14:31:32Z
Original Replica Count: 1
Scale Target GVKR:
Group: apps
Kind: Deployment
Resource: deployments
Version: v1
Scale Target Kind: apps/v1.Deployment
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal KEDAScalersStarted 3m52s keda-operator Scaler redis is built.
Normal KEDAScalersStarted 3m52s keda-operator Started scalers watch
Normal ScaledObjectReady 3m52s (x2 over 3m52s) keda-operator ScaledObject is ready for scaling
Unlike the deployment we created above, we can now see there are 2 replicas:
kubectl get deployments.apps web-app
NAME READY UP-TO-DATE AVAILABLE AGE
web-app 2/2 2 2 19m
You can of corse adjust this use case as wild as you imagination can go ;) and was mainly to emphasis how KEDA is another “must have” controller to help these common event driven use cases on-premise as we saw in this example which used redis and could have as easily used rabbitmq / sqs etc.
 KEDA | Kubernetes Event-driven Autoscaling
KEDA | Kubernetes Event-driven Autoscaling
I created a gist of a Taskfile.yml which has this demo avail in the following gist https://gist.github.com/hagzag/6f66c357e8c511c22b84365df68fff11 to run it:
git clone https://gist.github.com/6f66c357e8c511c22b84365df68fff11.git
cd 6f66c357e8c511c22b84365df68fff11
task setup
# check what was done - kubectl get po -A
task demonstrate-scale
# check that the web-app in keda-demo namespace is scaling from 1-2
Hope you enjoy this style of posts, I know I do … :) Thanks, HP

